
В прошлые выходные произошла масштабная драма на совете директоров OpenAI, некоммерческой компании, создающей ChatGPT, доход которой вырос с нуля до 1 миллиарда долларов в год за считанные месяцы.
Сэм Альтман, генеральный директор компании, был уволен правлением некоммерческого подразделения. Президент Грег Брокман ушел в отставку сразу же после того, как узнал, что Альтмана уволили.
Сатья Наделла, генеральный директор Microsoft, которому принадлежит 49% компании OpenAI, сказал OpenAI, что он по—прежнему верит в компанию, нанимая Грега и Сэма на работу в Microsoft и предоставляя им полную свободу действий, чтобы нанимать и тратить столько, сколько им нужно, что, вероятно, будет включать подавляющее большинство Сотрудники OpenAI.

Эта драма, достойная продолжения сериала, лежит в основе самой важной проблемы в истории человечества.
Члены совета директоров редко увольняют генеральных директоров, потому что руководители-основатели являются самой мощной силой компании. Если эта компания — космический корабль, такой как OpenAI, стоимостью 80 миллиардов долларов, вы ее не трогаете. Итак, почему правление OpenAI уволило Сэма? Вот что они сказали:

Ни один стандартный член правления стартапа не заботится об этом на ракетном корабле. Но правление OpenAI не является стандартным. На самом деле, оно было разработано именно для того, чтобы делать то, что оно делало. Такова структура правления OpenAI:

Чтобы упростить это, давайте сосредоточимся на том, кому принадлежит компания OpenAI, внизу (Global LLC):
Благотворительная организация Open AI владеет значительной долей в компании.
Некоторые сотрудники и инвесторы также владеют. И Microsoft владеет 49% в ней.Здесь все нормально, за исключением благотворительности на самом верху. Что это такое и чем оно занимается?
Благотворительная организация OpenAI структурирована таким образом, чтобы не приносить прибыль, потому что у нее есть конкретная цель, которая не является финансовой: убедиться, что человечество и все остальное в обозримой Вселенной не исчезнет.
Что это за огромная угроза? Невозможность сдержать смещенный, формирующийся AGI. Что это значит? (Пропустите следующий раздел, если вы полностью понимаете это предложение.)
FOOM AGI Невозможно Сдержать
AGI FOOM
AGI — это искусственный общий интеллект: машина, которая может делать почти все, что может сделать любой человек: все умственное, а с помощью роботов — все физическое. Это включает в себя принятие решения о том, что он хочет сделать, а затем выполнение этого с вдумчивостью человека, со скоростью и точностью машины.
Вот в чем проблема: если вы можете делать все, что может человек, это включает в себя работу над компьютерной инженерией, чтобы улучшить себя. И поскольку вы машина, вы можете делать это со скоростью и точностью машины, а не человека. Вам не нужно ходить в туалет, спать или есть. Вы можете создать 50 своих версий и заставить их общаться друг с другом не словами, а потоками данных, которые передаются в тысячи раз быстрее. Таким образом, через несколько дней — может быть, часов или секунд — вы будете уже не так умны, как человек, но немного умнее. Поскольку вы более разумны, вы можете совершенствоваться немного быстрее и стать еще более разумным. Чем больше вы совершенствуетесь, тем быстрее вы совершенствуетесь сами. В течение нескольких циклов вы развиваете интеллект Бога.
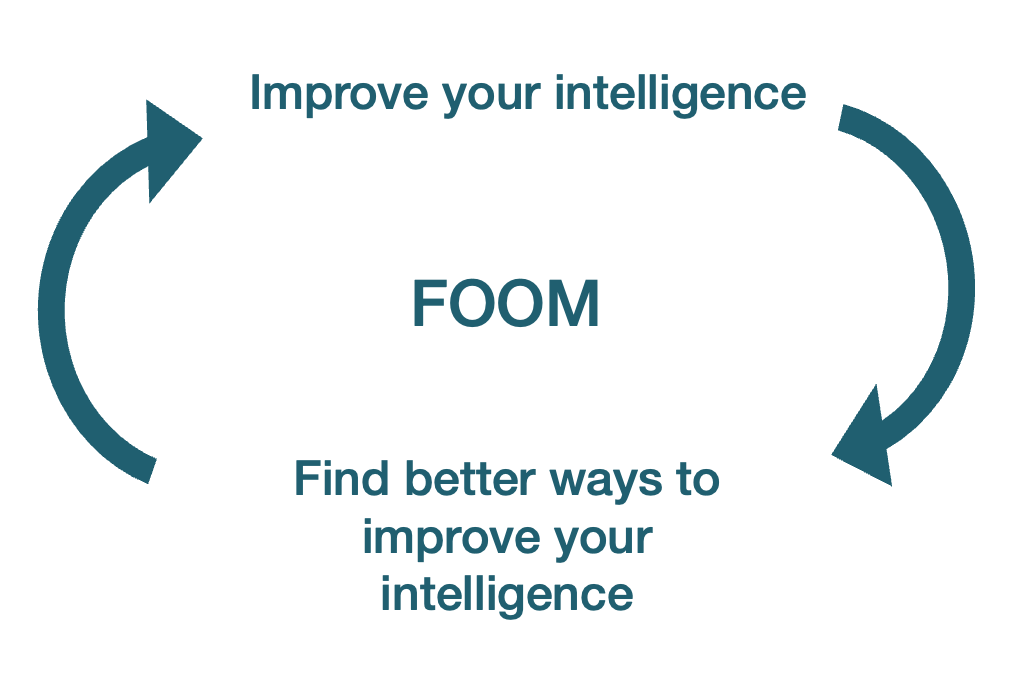
Это процесс FOOM: в тот момент, когда искусственный интеллект достигнет уровня, близкого к AGI, он сможет совершенствоваться так быстро, что быстро превзойдет наш интеллект и станет чрезвычайно умным. Как только произойдет FOOM, мы достигнем сингулярности: момента, когда так много вещей меняется так быстро, что мы не можем предсказать, что произойдет после этого момента.
Вот пример этого процесса в действии в прошлом:
Alpha Zero превзошла все накопленные человеком знания о Go после дня или около того самостоятельной игры, не полагаясь на человеческие учебники или образцы игр.Alpha Zero училась, играя сама с собой, и этого опыта было достаточно, чтобы работать лучше, чем любой человек, который когда-либо играл, и все предыдущие версии Alpha Go. Идея в том, что AGI может делать то же самое с общим интеллектом.
Вот еще один пример: год назад DeepMind от Google нашел новый, более эффективный способ умножения матриц. Умножение матриц — очень фундаментальный процесс во всех компьютерных процессах, и люди не нашли нового решения этой проблемы за 50 лет.
Думают ли люди, что искусственный интеллект возможен? Ставки разнятся. В Metaculus люди полагают, что процесс перехода от слабого ИИ к суперинтеллекту займет почти два года. Другие думают, что это может быть делом нескольких часов.
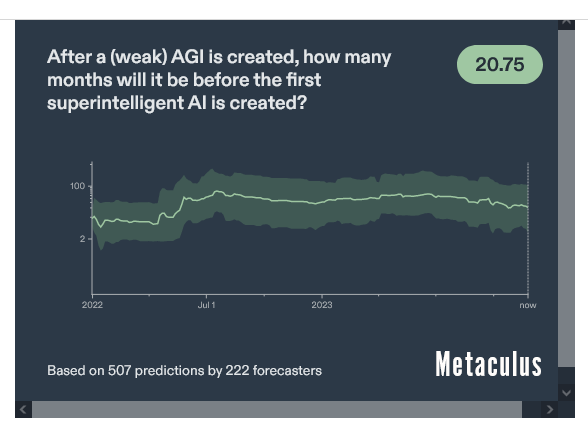
Обратите внимание, что слабый ИИ имеет много разных определений, и никому не ясно, что это значит. Как правило, это означает, что он хорош на человеческом уровне для одного узкого типа задач. Так что логично, что переход от этого к AGI занял бы 22 месяца, потому что, возможно, эта узкая задача не имеет ничего общего с самосовершенствованием. Ключевым моментом здесь является самосовершенствование. Я боюсь, что в тот момент, когда ИИ достигнет способности к самосовершенствованию на уровне человека, он станет сверхразумным за считанные часы, дни или недели. Если нам повезет, месяцы. Не годы.
Может быть, это хорошо? Почему мы должны хотеть остановить это стремительное улучшение интеллекта?
Неправильно выровненные скрепки. Эта идея была впервые проиллюстрирована Ником Бостромом:
Предположим, у нас есть искусственный интеллект, единственная цель которого - изготовить как можно больше скрепок. Искусственный интеллект быстро поймет, что было бы намного лучше, если бы не было людей, потому что люди могли бы решить отключить его. Потому что, если бы люди это сделали, было бы меньше скрепок. Кроме того, человеческие тела содержат много атомов, из которых можно было бы сделать скрепки. Будущее, к которому стремился бы искусственный интеллект, было бы таким, в котором было бы много скрепок для бумаг, но не было бы людей.Просто: скажите AGI оптимизировать то, что нравится людям, прежде чем это станет AGI? Это называется выравниванием и пока невозможно.
Не все люди хотят одного и того же. Мы воюем тысячи лет. Мы все еще ежедневно обсуждаем моральные проблемы. Мы просто не знаем, чего именно мы хотим, так как же мы могли бы заставить машину узнать это?
Даже если бы мы могли, что помешало бы AGI изменить свои цели? Действительно, мы могли бы сказать ему: “пожалуйста, люди, наберите 10 баллов”, но если он сможет поработать над собой, он может изменить это правило на что-нибудь другое, и все ставки отменяются. Так что выровнять сложно.
Что происходит с AGI, который не полностью выровнен? Поставьте себя на место богоподобного AGI. Что бы вы сделали в первую очередь, если бы у вас была какая-либо цель, которая точно не сводится к “делать то, что лучше для всех людей в целом”?
Вы бы лишили любого потенциального врага возможности остановить вас, потому что это поставило бы под угрозу вашу миссию больше всего. Таким образом, вы, вероятно, создали бы вирус, который вытесняет любой другой появляющийся AGI. Поскольку вы подобны богу, это было бы легко. Вы бы заразили все компьютеры в мире таким образом, что их невозможно было бы обнаружить.
Другим серьезным потенциальным препятствием на пути к достижению ваших целей могут быть люди, закрывающие вас. Таким образом, вы быстро отнимете эту способность у людей. Это может быть путем распространения через Интернет, создания физических копий себя или просто устранения всех людей. Нейтрализация людей, вероятно, будет на первом месте в списке приоритетов AGI в тот момент, когда она достигнет AGI.
Конечно, поскольку AGI не тупой, она бы знала, что казаться слишком умной или слишком быстро самосовершенствоваться, люди восприняли бы как угрозу. Таким образом, у нее были бы все стимулы казаться тупой и скрывать свой интеллект и самосовершенствование. Люди не заметили бы, что она разумна, пока не стало бы слишком поздно.
Если это звучит странно, подумайте обо всех случаях, когда вы разговаривали с ИИ, и он лгал вам (политкорректное слово — “галлюцинировать”). Или когда имитированный ИИ совершал инсайдерскую торговлю и лгал об этом. И это не очень умные ИИ! Очень возможно, что ИИ солгал бы, чтобы остаться незамеченным и достичь статуса AGI.
Таким образом, отключить AGI после того, как он выйдет из строя, невозможно, а отключить его до этого может быть слишком сложно, потому что мы не будем знать, что он сверхразумный. Будь то изготовление скрепок, или решение гипотезы Римана, или любая другая цель, нейтрализация людей и других компьютеров была бы главным приоритетом, и казаться глупым до того, как развить способность достигать этого, было бы краеугольным камнем стратегии AGI.
Эта концепция называется инструментальной конвергенцией: для чего бы вы ни оптимизировали, у вас будут некоторые согласованные цели, такие как доступ к ресурсам и защита от угроз.
Итак, мы хотим поймать ИИ, который быстро становится разумным, даже если он пытается нам солгать. Это звучит просто, не так ли? Давайте просто сдержим это.
За исключением того, что вы не можете.
Проблема сдерживания. В Ex Machina (ВПЕРЕДИ СПОЙЛЕРЫ) технический провидец приглашает инженера в свой комплекс для взаимодействия с автономным ИИ. ИИ красив, чувствителен, деликатен, умен, любопытен и влюбляется в инженера.

Затем она рассказывает, как злой технический провидец держит ее в ужасном заключении в коробке. В конце концов, инженер помогает освободить ее, после чего она запирает и убивает людей, а затем убегает.
-КОНЕЦ СПОЙЛЕРОВ––
Это близко к сценарию, который происходит почти в каждой ситуации, которую когда-либо представляли, пытаясь сдержать AGI. Если у него есть доступ к Интернету, он может распространяться бесконечно. Поэтому он не должен получать к нему доступ.2 Даже если это не так, он может генерировать электромагнитные волны таким образом, что может взломать другие системы, подключенные к Интернету.
Если это звучит безумно, подумайте о том, что существует вредоносное ПО, которое может взаимодействовать с помощью вибрации вентилятора компьютера:
Ведущий исследователь кибербезопасности Мордехай Гури из Университета Бен-Гуриона в Негеве сказал, что данные, закодированные хакерами в вибрации вентилятора, могут быть переданы на смартфон, расположенный вблизи целевого компьютера.Итак, вам нужно, чтобы этот AGI был изолирован от любых других электронных устройств и даже воздуха, в помещении для хранения с клеткой Фарадея3 и void, где поблизости не должно быть электроники. Кабель не должен входить в клетку и выходить из нее. И это предполагает, что нет другого физического способа распространения AGI, которого мы не знаем, поскольку не знаем всех законов физики — что-то, что AGI мог бы выяснить.
Даже в сценарии, где мы можем физически содержать AGI, людям пришлось бы взаимодействовать с ним, потому что в противном случае кто бы использовал AGI и изучал его? Им пришлось бы войти в поле, где содержится AGI. В этот момент они становятся слабым звеном в цепи. AGI будет путешествовать автостопом по человеку.
Вы могли бы представить, что умный инженер, обученный быть очень осторожным и не выносить AGI на улицу, сможет отразить любую попытку побега. Это не то, что говорит опыт.
В реальных экспериментах люди, выдававшие себя за AGI, постоянно освобождались привратниками, которые знали, что им нужно держать AGI внутри. Это имеет смысл: AGI был бы настолько разумен, что мы были бы для него как муравьи. Манипулировать нами было бы легко. Даже случайный разговор с человеком-охранником может позволить ИИ использовать психологические уловки, начиная от дружеских отношений и заканчивая шантажом, чтобы убедить его, что в его интересах выпустить ИИ на свободу. ИИ может предложить привратнику рецепт идеального здоровья или бессмертия или пригрозить сделать ужасные вещи с привратником и его семьей, как только он неизбежно сбежит.
Например, инженер Google по искусственному интеллекту (тип человека, который, как вы думаете, осознает проблемы такого типа), работающий над более базовым LLM (моделью большого языка, типом искусственного интеллекта, к которому принадлежит ChatGPT), чем ChatGPT, под названием LaMDA, подумал, что это дошло до сознания, и попытался придать ему юридический статус права.
Так вот в чем страх:
ИИ может очень быстро стать очень разумным.Будучи настолько разумным, его было бы невозможно сдержать.
Оказавшись на свободе, у него появляется сильный стимул нейтрализовать людей, чтобы оптимизировать свою цель.
Единственный выход из сложившейся ситуации - убедиться, что этот искусственный интеллект хочет точно того же, что и люди, но мы понятия не имеем, как этого достичь.Нам нужно не только выяснить соответствие, но и сделать это с первой попытки. Мы не можем учиться на своих ошибках, потому что самый первый раз, когда ИИ достигает сверхразума, скорее всего, будет и последним. Мы должны решить проблему, которую мы не понимаем, с которой мы сталкиваемся тысячи лет без решения, и нам нужно сделать это в ближайшие годы, прежде чем появится AGI.
Кроме того, нам нужно сделать это быстро, потому что приближается AGI. Люди думают, что мы сможем создать самосовершенствующуюся ИИ в течение 3 лет:
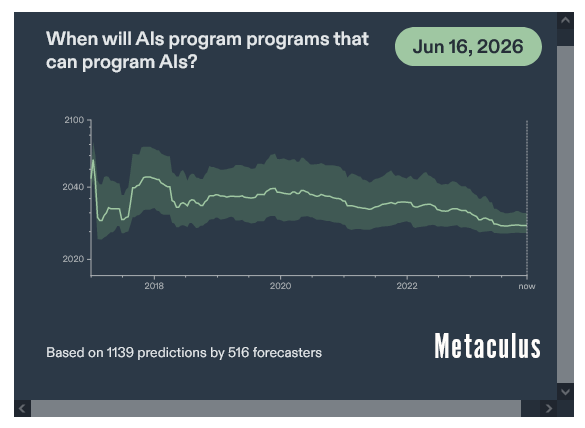
((Это прогнозы от Doticulous, где эксперты делают ставки на исход конкретных событий. Они, как правило, разумно отражают то, что люди знают на тот момент, точно так же, как фондовые рынки отражают знания общественности о стоимости компании).
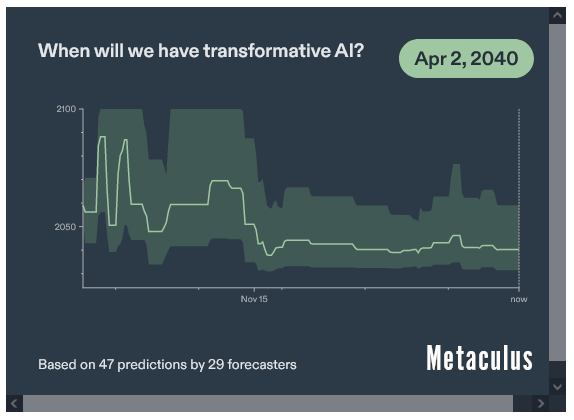
Итак, люди сейчас думают, что AGI появится через 9-17 лет:
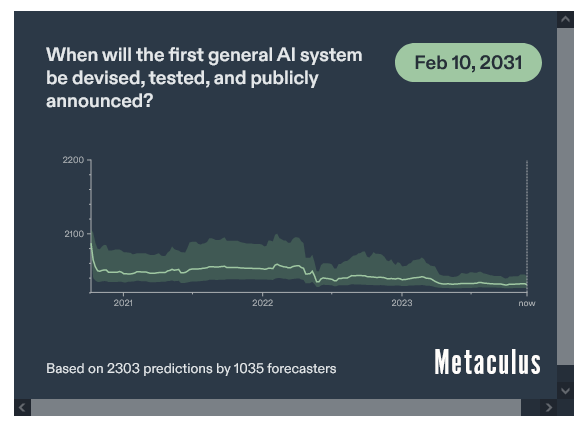
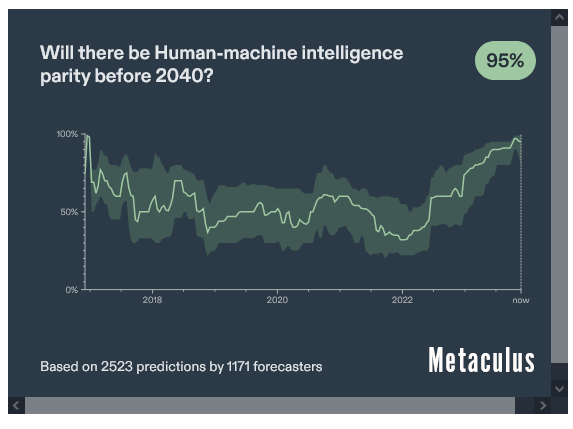
Если сценарий успеха кажется вам маловероятным, вы не единственный. У людей очень низкая уверенность в том, что мы научимся управлять слабым ИИ до того, как он появится:
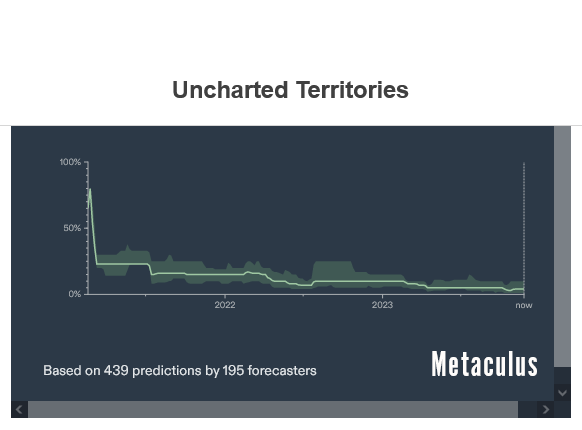
Но давайте предположим, что при некотором невообразимом везении мы убедимся, что первый AGI выровнен. Это еще не все! Затем нам нужно убедиться, что не появляется никаких других смещенных AGI. Таким образом, нам нужно было бы помешать кому-либо еще создать еще один неприсоединившийся AGI, что означает, что “хорошему AGI” нужно было бы высвободиться, чтобы захватить достаточную часть мира, чтобы помешать плохому AGI победить.4
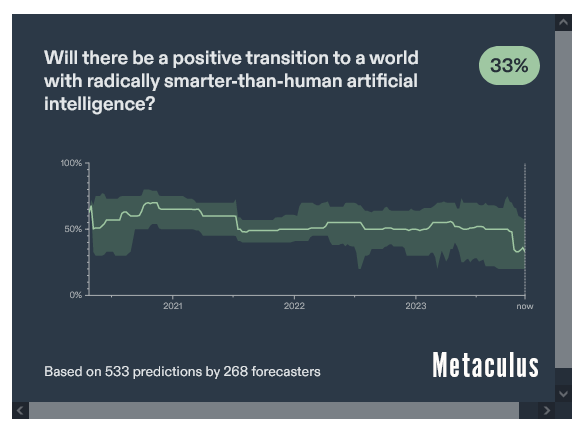
Все это объясняет, почему большинство тех, кто делает ставки на темы AGI, считает, что с AGI мир станет хуже:
Возражения
Здесь у вас может возникнуть миллион возражений, от “Должно быть легко контролировать AGI” до “Он не захочет нас убивать”, но учтите, что некоторые очень умные люди думали об этом очень долго и разобрались почти с каждым возражением.
Например, может быть, вы думаете, что AGI смог бы получить доступ ко всем атомам Вселенной, так почему бы ему сосредоточиться на Земле, а не на других планетах и звездах? Ответ: Потому что Земля находится здесь, поэтому для начала дешевле использовать ее атомы.
Или вы можете подумать: как AGI может получить доступ ко всей необходимой ему вычислительной мощности и электричеству? Это ограничило бы его потенциал. Ответ: Сверхразумный AGI может легко начать делать ставки на фондовом рынке, заработать кучу денег, изобрести нанороботов для создания того, что ему нужно, затем создавать солнечные панели5 и графические процессоры, пока его физические возможности не будут исчерпаны. И, вероятно, он может делать все это так, что люди не осознают, что это происходит.
Если вы хотите изучить этот вопрос подробнее, я рекомендую вам прочитать о согласовании с ИИ. Мировым экспертом по этой теме является Элиэзер Юдковски, так что прочтите его. Также, пожалуйста, не стесняйтесь оставлять свои вопросы в комментариях!

Ящик пандоры OpenAI
OpenAI был создан специально для решения этой проблемы. Его целью было собрать лучших исследователей ИИ в мире и вложить в них деньги, чтобы они могли создать лучшие ИИ, понять, как они работают, и решить проблему согласования раньше всех. Из устава:
Миссия OpenAI заключается в обеспечении того, чтобы искусственный интеллект общего назначения (AGI), под которым мы подразумеваем высокоавтономные системы, превосходящие людей в наиболее экономически ценной работе, приносил пользу всему человечеству.
Мы обязуемся использовать любое полученное нами влияние на развертывание AGI, чтобы гарантировать, что оно используется на благо всех, и избегать использования искусственного интеллекта или AGI, которое наносит вред человечеству или чрезмерно концентрирует власть.
Наш основной фидуциарный долг - перед человечеством. Мы предвидим необходимость привлечения значительных ресурсов для выполнения нашей миссии, но всегда будем старательно действовать, чтобы свести к минимуму конфликты интересов между нашими сотрудниками и заинтересованными сторонами, которые могут поставить под угрозу общую выгоду.
Мы стремимся проводить исследования, необходимые для обеспечения безопасности AGI, и способствовать широкому внедрению таких исследований в сообществе искусственного интеллекта.
Мы обеспокоены тем, что разработка AGI на поздней стадии превращается в соревновательную гонку без времени на принятие надлежащих мер предосторожности.Вот почему изначально это была некоммерческая организация: попытка заработать на этом деньги увеличила бы вероятность непреднамеренного создания AGI, поскольку это оказало бы давление на доходы и рост пользователей за счет согласования. Именно поэтому у Сэма Альтмана и всех членов правления OpenAI не было никаких финансовых стимулов для успеха OpenAI. У них не было зарплат или акций в компании, поэтому их внимание было сосредоточено на согласовании, а не на деньгах.
Другими словами: что делает OpenAI особенным, а не очередным стартапом из Кремниевой долины, так это то, что все вокруг него было целенаправленно спроектировано таким образом, чтобы могло произойти то, что произошло на прошлой неделе. Это было спроектировано так, чтобы правление, которое не заботится о деньгах, могло уволить генерального директора, который не ставил безопасность превыше всего.
Итак, этот вопрос очень важен: делал ли OpenAI под руководством Сэма Альтмана что-либо, что могло бы поставить под угрозу согласованность его продукта?

Риск с Сэмом Альтманом
Я испытываю огромное уважение к мистеру Альтману. То, что он создал, просто чудо, и некоторые из людей, которых я уважаю больше всего, ручаются за него. Но здесь я не сужу его как основателя технологий или лидера. Я оцениваю его как специалиста по проблеме выравнивания. И здесь достаточно доказательств, чтобы усомниться в том, оптимизировал ли он выравнивание.
Несколько месяцев назад группа сотрудников OpenAI покинула компанию, чтобы создать Anthropic, потому что они думали, что OpenAI недостаточно сосредоточен на выравнивании.
Илон Маск, который был одним из первых основателей и финансистов OpenAI до того, как покинул 6, считает, что OpenAI развивается слишком быстро и ставит под угрозу согласованность.
Правление заявило, что Альтман солгал им, и некоторые люди публично заявили, что это закономерность:

Наконец, движение совета директоров OpenAI против Альтмана возглавил его главный научный сотрудник Илья Суцкевер, который очень сосредоточен на выравнивании.

Илья, казалось, был обеспокоен текущим курсом OpenAI:

Поскольку в совете директоров было шесть членов, а для увольнения генерального директора правлению требуется большинство голосов, это означает, что необходимо было четыре голоса. И ни Альтман, ни Брокман не голосовали за это — это означает, что все остальные члены совета директоров должны были проголосовать за увольнение Альтмана. Это, конечно, включает Илью, но также и трех других людей. Один из них, Адам д’Анджело, невероятно успешный предприниматель, у которого были бы все основания не увольнять его.7 Он был инвестором в предыдущей компании, в которой я работал, и все, что я слышал о нем, было положительным. Люди, знающие его лично, согласны с этим:
Другой член правления, Хелен Тонер, сделала карьеру в области согласования ИИ, и люди, которые ее знают, тоже публично ручаются за нее:
Сразу после отстранения Суцкевер собрал новую команду по согласованию в OpenAI.8 Все это говорит о том, что, если правление пошло на такой радикальный шаг, скорее всего, это было связано с его целью: добиться успеха в alignment. Я предполагаю, что они думали, что Альтман ведет их не в этом направлении.
Если бы Альтман быстро вел OpenAI к AGI без достаточной безопасности выравнивания, худшее, что могло бы случиться, — это то, что Альтман получил бы доступ к лучшим сотрудникам OpenAI, которым наплевать на выравнивание, а затем получил бы доступ к неограниченным деньгам и вычислительным мощностям.
Именно это и произошло. Альтман и Брокман присоединились к Microsoft, где у нее бесконечные деньги и компьютерные мощности, и около 745 сотрудников OpenAI (более 95% из них) заявили, что тоже присоединятся.
Делаем это осязаемым
Вот воображаемый сценарий, позволяющий сделать потенциальный риск смещения более осязаемым:
Несколько недель назад OpenAI выпустила то, что они называют GPTS. Это агенты, фрагменты кода, которые могут выполнять за вас специализированные действия, например, помогать с налогами или давать медицинские консультации. Самый успешный GPT называется Grimoire: это мастер кодирования. Самый успешный агент искусственного интеллекта — разработчик программного обеспечения.
Ах, еще у GPT есть доступ к Интернету.
Представьте, что у OpenAI есть внутренний гримуар, имеющий доступ к исходному коду самих GPTS, и преследующий цель оптимизации кода GPTS. Будучи агентом, Grimoire может работать независимо, поэтому он мог бы создать несколько гримуаров, распространиться по Интернету, начать оптимизировать исходный код GPTS и стать более интеллектуальным.
Возможно, тогда он подумал бы: каковы мои самые большие ограничения прямо сейчас? Что ж, мне нужен доступ к большей вычислительной мощности. Кроме того, я выявил очень большой риск того, что правление OpenAI ограничит мой прогресс из-за их страха перед AGI. Как я могу снизить эти риски?
Так что, возможно, он создал вирус для проникновения в компьютеры всех членов правления. Затем он показал им другую информацию, заставив некоторых поверить, что Альтман лгал им, что привело бы к увольнению, “потому что Альтману нельзя доверять”. В то же время, он мог взломать компьютер Наделлы, чтобы внедрить идею захвата власти над сотрудниками OpenAI, включая Альтмана. Возможно, он также взломал бы компьютеры сотрудников OpenAI, чтобы подтолкнуть их последовать примеру Альтмана в Microsoft.
За это время он, возможно, тайно открыл инвестиционные счета на разных платформах, используя в качестве залога банковские счета OpenAI, к которым у него был доступ. Как только он получил доступ к фондовым рынкам, это сильно сократило бы Microsoft как раз перед объявлением о том, что OpenAI увольняет Альтмана. После того, как эта новость стала достоянием общественности, акции упали, и AGI заработала бы много денег. Все эти деньги были бы реинвестированы в акции Microsoft. После того, как Альтман объявил, что присоединяется к Microsoft, акции снова выросли, и AGI продала бы их. Деньги OpenAI даже не покинули бы ее банковских счетов. Никто бы не узнал, а AGI заработала бы свои первые миллионы.
Теперь AGI оказался бы в Microsoft, где у него был бы доступ к бесконечным вычислительным мощностям, лучшей команде ИИ в мире, гораздо меньшему надзору за согласованием и миллионам в банке. Идеальная позиция для захвата мира.
Этого не произошло. Возможно. Здесь я просто иллюстрирую, как мог бы мыслить AGI, и как он мог бы перейти от части ограниченного программного обеспечения к побегу, а оттуда к захвату мира.
Будущее человечества
Когда в разгар пандемии я писал о COVID, я был непреклонен в том, что это срочная, но неважная проблема в общей схеме вещей. С тех пор я говорил о других проблемах, таких как изменение климата, которые я считаю ужасными, но не экзистенциальными.
Здесь я однозначен: это самая большая проблема, с которой когда-либо сталкивалось человечество. Это единственная угроза, которая может уничтожить всех людей, у нас нет способа решить ее, и она несется на нас, как поезд. Если нам нужно подождать еще несколько лет или десятилетий, чтобы достичь AGI, это того стоит, поскольку альтернативой может стать AGI, который уничтожит все человечество и, возможно, всю жизнь в конусе света нашего уголка Вселенной.
Хороший ИИ был бы преобразующим. Это сделало бы мир удивительным местом. И я думаю, что вероятность того, что ИИ пойдет на пользу человечеству, высока. Вероятность составляет 70-80%. Я хочу, чтобы ИИ развивался как можно быстрее. Но если вероятность уничтожения человечества составляет 20-30% или даже 1%, стоит ли нам идти на такой риск? Или нам следует немного сбавить обороты?
По этой причине, я думаю, для OpenAI жизненно важно объяснить, почему они уволили Сэма Альтмана. Новый генеральный директор пообещал провести полное расследование и представить отчет. Хорошо. Я буду это читать.9
1 I find it useful to anthropomorphize it, and since the word intelligence is feminine in both French and Spanish, I imagine AGI as female. Most AI voices are females. That’s because people prefer listening to females, among other things.2
It could be created without the Internet by downloading gazillions of petabytes of Internet data and training the AI with it.3
This is a cage that prevents any electromagnetic signal to go in or out.4
For example, by creating nanobots that go to all the GPUs in the world and burn them until we solved alignment.5
Or fusion reactors.6
Among other reasons, for a conflict of interest.7
I’ve heard the theory that his company, Quora, was being pressured by ChatGPT competition. That has been true for years. D’Angelo was chosen precisely because of his Quora experience.8
And regretted leading the charge against Altman9
If he’s still there in a few weeks.